Hello, if you have any need, please feel free to consult us, this is my wechat: wx91due
Assignment: MTHM503
Deadline: 29th July 2024 at 12:00pm
(midday)
Introduction
This assignment consists of three sections. In all sections, you are free to use either R or Python. All answers should be submitted in a rendered version of a Jupyter/R Markdown notebook. The rendered files can be either in HTML or PDF format.
Your Jupyter/R Markdown notebooks should be clearly organised and anno- tated numerically according to the corresponding questions. In these exercises, please focus on writing clear, understandable code (with comments where neces- sary). The code you submit will be evaluated not only for its accuracy but also for its clarity. Make sure to explain your approach and illustrate key decisions taken in your solutions.
You should complete this assignment alone - strict disciplinary action will be taken for any collusion or plagiarism. Furthermore, you must not use AI tools such as ChatGPT to produce answers for you. If you fail to acknowl- edge such use of AI tools then you will be committing an academic ofence.
If markers suspect that you have used AI tools then you will be required to attend a viva (oral exam) in order to demonstrate your understanding.
Please refer to the Faculty guidelines on plagiarism https://as.exeter.ac.uk/ academic-policy-standards/tqa-manual/aph/managingacademicmisconduct/ and the use of generative AI https://libguides.exeter.ac.uk/referencing/ generativeai.
A. Wage modelling [35 marks]
You have been given a dataset which contains income and demographic infor- mation for males living in the central Atlantic region of the United States. Each row in dataset file wage .csv contains individual information. Your task is to build a predictive model for wage.
(i) Plot the data to explore the relationships between wage and the other variables. Comment on any patterns/trends that you have observed.
(ii) Perform polynomial regression to predict wage using age. Use 10-fold cross-validation to select the optimal degree d for the polynomial. Hint:
The k-fold estimate is computed by
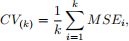
where MSE stands for mean squared error. What degree was chosen? Produce the plot of 10-fold CV error curve to support your choice.
(iii) Split the dataset into training and testing sets retaining 80% for training and 20% for testing.
(iv) Fit a GAM model on the training data using wage as the response and age as the predictor. Evaluate the model obtained on the test set, and explain the results obtained.
(v) Fit a spline regression on the training data using wage as the response and age as the predictor. You need to specify two parameters: the degree of the polynomial and the location of the knots. Please explain your choice. Evaluate the model obtained on the test set, and explain the results obtained.
B. What factors influence weight? [30 marks]
The data within weight height .csv contains measurements of individuals’ heights, weights, their age and their sex.
Build a regression model to explain the patterns in individuals’ weights in these data. You should aim to present a parsimonious model: one that is just complex enough to explain the data and not too complex to cause overfitting.
Your answer should demonstrate how you came to choose this model, which should likely involve graphs (three maximum) and text (three short paragraphs maximum).
C. Clustering the gene expression data set [35 marks]
Unsupervised methods are often used to analyse genomic data. The file gene file .csv contains brain cancer gene expression from Curated Microarray Database (CuMiDa) with the following information:
• 4 cancer types
• 54675 gene expression measurement
• 117 cancer cell lines
Each cell line is labelled with a cancer type. The data has 117 rows and 54,677 columns
(i) Scale the variables (genes) to have mean zero and standard deviation one. Explain why the data should be scaled.
(ii) Perform dimensionality reduction using PCA on the data after scaling and use the scree plot to choose the optimal number of retained principal components.
(iii) Apply hierarchical clustering on the first few principal component score vectors using the correlation-based distance and plot the dendrogram. Do the genes separate the samples into the four groups?
(iv) Perform hierarchical clustering on the full data set. Comment whether the results are diferent from the ones that you have obtained with a reduced data set.