Hello, if you have any need, please feel free to consult us, this is my wechat: wx91due
GR5242 HW01 Problem 2: Dropout as a form of regularization
Instructions: This problem is an individual assignment -- you are to complete this problem on your own, without conferring with your classmates. You should submit a completed and published notebook to Courseworks; no other files will be accepted.
Description: In this exercise we will try to understand regularizing effects of Dropout method which was initially introduced in the deep learning context to mitigate overfitting, though we intend to study its behavior as a regularizer in a rather simpler settting.
Regression
Indeed, linear models correspond to a one layer neural networks with linear activation. Denote 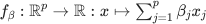 to represent the output of such network. Given n samples
to represent the output of such network. Given n samples 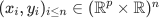 we want to regress the response onto the observed covariates using the following MSE loss:
we want to regress the response onto the observed covariates using the following MSE loss:
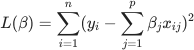
In the current atmosphere of deep learning practice, it is rather popular to have moderately large networks in order to learn a task (we will see more on this later in the course). This corresponds to having  in our setting which allows more flexibility in our linear model. However, in these cases where the model can be too complicated one can use explicit regularization to penalize complex models. One way to do so is ridge regression:
in our setting which allows more flexibility in our linear model. However, in these cases where the model can be too complicated one can use explicit regularization to penalize complex models. One way to do so is ridge regression:
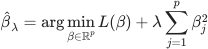
Question 1: Show that 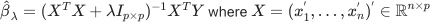 and
and 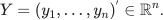
Dropout
We now present the connection between dropout method and ridge regression (outlined in more detail in Wager et al.)
To recap, dropout randomly drops units along with their input/output connections. We now want to apply this method to our simple setting. Let us define the indicator random variable Iij to be whether the 'th neuron is present or not in predicting the response of the i'th sample. More explicitly, the ouput of the network for 'th sample becomes 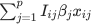 where
where
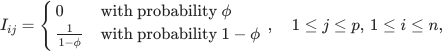
drawn independently from the training dataset. Note that E[Iij] = 1, thus the output of the
Question 2: Write down explicitly the loss function after using the dropout as a function of 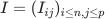 denoted by L(β, I).
denoted by L(β, I).
It can be shown that SGD + Dropout is in some sense equivalent to minimizing the loss function L(β, I) on average. Related to this point, the following problem justifies why dropout can be thought as a form of regularization.
Question 3: Suppose the feature matrix 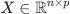 have standardized features (norm of each column is one). Show that the solution to the following problem corresponds to a ridge regression with
have standardized features (norm of each column is one). Show that the solution to the following problem corresponds to a ridge regression with 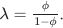
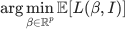
where the expectation is over the randomness of indicator random variables.
Hint: You can assume that taking derivative can pass through expectation.