MATH2319 - Machine Learning
Course Project Phase 1
Assessment Weight: 15% (Marked out of 100 points)
Project Group Membership Finalisa"on Due: Sunday March 31st, 11:59pm
Report Due: Sunday April 21st , 11:59 pm (Online submission)
Feedback Mode
Feedback will be provided using Canvas.
Learning Objec"ves Assessed
This assessment task supports CLOs 1, 2, 3, and 4.
Summary
In this course, you will be required to complete a major group course project. For your project, you can work alone if you like; or you can work in groups of 2 or 3 students (and no more). The idea with the course project will be to apply what you have learned in class and more importantly, to have fun! The project shall entail the following tasks.
Project Phase 1 (This Assessment) :
Data pre-processing (dealing with missing values, dropping ID-like columns, data aggrega!on, etc.) as appropriate.
Data explora!on and visualisa!on (charts, graphs, interac!ons, etc) as appropriate.
Project Phase 2:
Predic!ve modeling as appropriate.
Purpose
The purpose of the course project is to apply machine learning techniques on a problem of your own choosing using Python and the Scikit-Learn module. The project will be hands-on and it will require you to select appropriate performance metrics for your problem and also properly compare performance of different methods. You will also gain experience on documen!ng your findings and your code in a Jupyter Notebook environment. In addi!on, you will get the opportunity to receive feedback on your performance and the report that you submit.
Course Project Instruc"ons and Assessment Criteria:
Compliance with University Policies
1. You may not submit any previous work from RMIT or any other place for this course project, even if it was done by yourself. RMIT policy is that a par!cular work can be submi#ed only once for credit.
2. You may not use the datasets in the inspira!on projects nor any dataset we use in this course. These specific datasets are included in the list of "Blacklisted Datasets" below.
Programming Language Requirements
The project must be done in Python 3.6 or above.
Submission Instructions
NOTE 1: Canvas can occasionally become a rather unreliable piece of so$ware, unfortunately. So please follow all technical submission instruc!ons for your assessments so that we can correctly iden!fy your files for marking purposes. Thank you.
NOTE 2: If you have 2 or 3 members in your group, then ONLY ONE of the members must make the submission.
NOTE 3: For both reports, please make sure you include your group name as well as full name(s) and student ID(s) of all group members (EVEN IF you are the only person in the group). Thank you.
WARNING 1: We cannot run plagiarism check so#ware on zipped submissions, so zipped submissions will NOT be marked and they will not receive any points.
WARNING 2: We require an HTML file for a plagiarism check. This is because we cannot run plagiarism check so#ware on Jupyter notebook files, so submissions missing the HTML file will NOT be marked and they will not receive any points.
Suppose you are in Group 23.
For Phase 1: You need submit the following 3 files (please do not zip them):
1. Phase1_Group23.csv (your Phase 1 input data as a single CSV file. The idea here is that we should be able to replicate your Phase 1 results successfully by running your notebook with this input CSV file.)
2. Phase1_Group23.ipynb (your Jupyter notebook file)
3. Phase1_Group23.html (an HTML file directly compiled from your Jupyter notebook file)
For Phase 2: You need submit the following 3 files (please do not zip them):
1. Phase2_Group23.csv (your Phase 2 input data as a single CSV file. The idea here is that we should be able to replicate your Phase 2 results successfully by running your notebook with this input CSV file.)
2. Phase2_Group23.ipynb (your Jupyter notebook file)
3. Phase2_Group23.html (an HTML file directly compiled from your Jupyter notebook file)
Important Phase 2 Note: Please do NOT include your Phase 1 reports or its contents with your Phase 2 submissions. You can, however, make some changes with your Phase 1 tasks if you need to, and then ONLY include these changes with your Phase 2 report with some explana!on for these changes.
NOTE 4: Canvas File Renaming: If you resubmit a file on Canvas, say a file called "Phase1_Group23.html", Canvas will rename it to "Phase1_Group23-2.html" in the second submission, and then to "Phase1_Group23-3.html" in the third submission, etc. That will be OK as far as file naming is concerned, because this is how Canvas works.
Other technical instruc"ons you need to follow while submi!ng your course project reports as well as applicable penal"es are explained in detail on this page.
Project Phases
Phase 1 Due at the End of Week 6 (15%):
- Data cleaning and preprocessing (dealing with missing values, dropping ID-like columns, data aggrega!on, etc.) as appropriate.
- Data explora!on and visualisa!on (charts, graphs, interac!ons, etc) as appropriate.
Phase 1 Report Sample: Here
Phase 2 Due at the End of Week 12 (25%):
- Predic!ve modelling of data as appropriate.
Inspira"on for Data Pre-processing/ Predic"ve Modelling is here.
DISCLAIMER: These reports are provided to give you a rough idea on what you could possibly do for your project. You should not assume that these reports fully address all the requirements as outlined in this Course Project Info page. You must read all the instruc!ons herein and follow them closely for full credit.
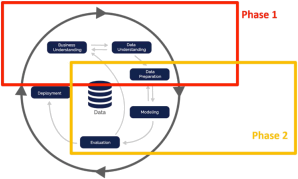
This is how CRISP-DM looks in your course project:
Some Terminology
Many names for the same things:
Some names for columns in a dataset: features/ a#ributes/ variables
Some names for rows in a dataset: instances/ observa!ons/ records
Some other names for the target feature (this is the feature you will predict): response variable/ dependent variable
Some other names for descrip"ve features (these are the features you will use for making predic!ons): independent variables/ explanatory variables
One-Hot-Encoding (OHE):
This is a data pre-processing step that we will cover in detail in Week 3: Data Prep. OHE essen!ally creates q new binary features for a categorical feature with q different levels.
Example: Suppose you have a "state" feature for US customers in a dataset. Upon OHE, 50 new binary features (taking on the value of either 0 or 1) will be created, one for each US state. For a customer living in California, the state binary feature corresponding to California will be 1 and all other state binary features will be zero.
A$er OHE, you will not need the original state feature.
This is how we convert categorical features into numerical features as part of data pre-processing for predic!ve modeling/ machine learning.
Dataset Requirements & Restrictions
1. Dataset selec"on: This is a loosely defined project to give you the maximum level of flexibility. In par!cular, you will need to choose a project dataset yourself.
2. Problem type: Your project needs to be on a supervised machine learning problem. That is, you need to have a target feature that needs to be predicted. Both classifica"on (categorical target feature) and regression (numeric target feature) problems will be accepted.
3. Dataset resources: There are no hard restric!ons on the dataset that you can select for your project. You can choose a public dataset from popular data repositories or you can find some other suitable dataset from any website on the Internet or whatever. You can also use data from your work. Please check the bo#om of this page for some suggested resources for finding a suitable dataset for your project.
4. Guidance for selec"ng a dataset: As a friendly advice, you might want to select a dataset in line with your future career plans and the par!cular industries you are interested in. For example, if you plan on working in the banking industry (or conduc!ng academic research in this area), you might want to select a finance related dataset so that your course project can be a talking point during your interviews.
5. Blacklisted datasets: The dataset you choose apparently needs be appropriate for a major machine learning course project. For instance, the following datasets are blacklisted:
Boston Housing/ Iris/ Titanic/ US Adult Income Dataset/ Wine/ Wisconsin Breast Cancer
Clarifica!on: The "Diamond Prices" dataset is NOT blacklisted - you can use it in your projects.
6. Minimum requirements: Your dataset must have at least 200 rows and at least 8 descrip"ve features. To be clear, your dataset needs to have at least 8 descrip!ve features a#er dropping all unnecessary features (that you will not use) but before one-hot-encoding of any categorical descrip!ve features. There is no requirement on the data types of your descrip!ve features: they can be all numeric, all categorical, or a mix.
7. Random sampling for very large datasets: There is no upper limit on the number of rows, but if your dataset has more than 5000 rows, you might want to select a random subset with at most 5000 rows so that you do not fry your laptop! That is, you will not lose any points for selec!ng only a rela!vely small subset of rows in case your dataset has too many rows.
8. Exclusion of "me series datasets: In general, the rows in your dataset need to be independent (without any correla!ons) for ML algorithms to work properly. As an example, if you think about Google's daily stock prices (as in "one day per row"), you will see that these observa!ons are correlated. On the other hand, if you think about customers of a bank (as in "one customer per row"), these observa!ons are independent and uncorrelated (for the most part). For this reason, datasets for which the rows are correlated such as "me series datasets will not be eligible for your course project. There are ways to tackle this !me series dependency within a machine learning se%ng, but they are beyond the scope of this course.
9. Compe""on datasets: Kaggle or similar compe!!on datasets will be accepted provided that the work you submit is your own personal work.
Some Resources for Data
Try this! Google's dataset search tool is here. You can search for any subject/ keyword you like.
UCI ML Repository is here.
KEEL Repository is here.
Open ML Repository is here.
Our GitHub page here hosts some datasets.
Project Submission Modes
For your course project, you will have the op!on to choose from two different submission modes: Advanced Submission or Regular Submission:
Advanced Submission Mode: The purpose of this mode is to iden!fy truly "high dis!nc!on" submissions. Specifically, this mode is for advanced students who are willing to put in extra effort for the full 100 points by undertaking addi!onal tasks. Specifically, you will be required to complete two addi!onal tasks as below in the Advanced Submission mode:
Addi"onal Task for For Phase 1 Advanced Mode: A Literature Review sec!on with at least 600 words (worth 15 points out of 100)
Addi"onal Task for For Phase 2 Advanced Mode: An addi!onal sec!on on Neural Networks applied to your par!cular problem with a narra!ve of at least 600 words (worth 15 points out of 100)
Details of these two addi!onal tasks are provided in relevant Assessment Criteria sec!ons below.
Regular Submission Mode: For this mode, you will not be required to undertake any one of the above addi!onal tasks.
Bonus Points for Regular Submissions: Occasionally we will come across regular submission reports that exceed the expecta!ons for this assessment in the regular submission mode. To differen!ate these reports and recognise your extra hard work in such cases in the regular submission mode, we will be awarding discre!onary bonus points for regular submissions not to exceed 5 points. The amount of bonus shall be determined by the assessment marker(s), who will try to be as fair as possible across the en!re batch of submissions in the class.
Clarifica"on 1: You can make an advanced submission for both phases or just for a single phase. That is, if you like, you can make a regular submission for Phase 1 and an advanced submission for Phase 2, or vice versa.
Clarifica"on 2: Suppose yours is a regular submission. That is, you did not undertake the relevant addi!onal task above in your report. In this case, the maximum score you can get will be 90 out of 100 for your submission (up to 85 base points for the report itself plus up to 5 points in bonuses).
Clarifica"on 3: The amount of bonus points will be determined on a case-by-case basis and they can be different for each phase report you submit. For instance, you might get no bonus points for your Phase 1 report, but the full 5 points for your Phase 2 report.
Clarifica"on 4: Your report will be eligible for some bonus points only if your base score (without any bonuses) is the full 85/100. That is, if your report's base score is below 85/10, your report will not be eligible for any bonus points. This is because the bonus points will be reserved only for truly outstanding project reports.
Clarifica"on 5: Suppose yours is an advanced submission. That is, you undertook the relevant addi!onal task above in your report. In this case, the maximum score you can get will be 100 out of 100 for your submission.
Project Instructions
1. Data preprocessing is more than just filling in missing values or removing outliers. We suggest you have a look at our data preprocessing tutorial and Chapter 3 in the textbook that discusses data preprocessing.
2. Your report needs to contain a certain minimum number of different plots as part of the data explora!on and visualisa!on tasks. Please see Plo!ng Requirements sec!on below for the specific minimum number of different plots you need to include in your report.
3. In your project, you must try a certain minimum number of different ML algorithms on your problem, perform some sort of feature selec!on & hyper-parameter tuning, and you must also present performance sta!s!cal comparisons to indicate which method seems to work best. If you like, you may also use algorithms not covered in class (deep learning etc). Please see Algorithm Requirements sec!on below for the specific minimum number of different ML algorithms you need to experiment with.
4. Your narra"ve (that is, the text that you write excluding any Python code) in each one of your project reports must be at least 1500 words (plus an addi"onal 600 words for Advanced Submission Modes). And ideally it should be less than 3500 words (plus an addi!onal 600 words for Advanced Submission Modes). As a clarifica!on, Python code comments do not count as narra!ve. This limit is to ensure that your report contains adequate material for a major course project.
5. To be clear, our expecta"on here is professional project reports, not a quick and dirty summary of how your Python code works. For more informa"on on this, please see the "Good Wri"ng Prac"ces" Sec"on on this page.
6. You are allowed to use code in our course materials as well as code on our website (www.featureranking.com) with proper acknowledgement.
7. Your report will be checked against plagiarism using Turni"n so#ware. Some similari!es in computer code will be OK, but excessive copy & paste of text from other people's work (INCLUDING our course material as well as our website) will be closely scru!nised. So, please do not submit our case study back to us as your course project by simply plugging in your dataset!! This will be very uncool and it will be plagiarism. That is, your project report must be in your own words. For addi!onal important informa!on on what cons!tutes plagiarism, please see the "Integrity and Plagiarism" Sec!on in our Course Policies here.
8. Any suspected cases of plagiarism will be dealt with on a case-by-case basis in accordance with RMIT's plagiarism policies together with the penal!es that come with these policies. A possible outcome might be that you receive a mark of zero for your submission due to plagiarism. Depending on the nature of the plagiarism, more severe penal!es might also apply.
9. Your reports for both phases need to contain a Table of Contents. We are aware that some!mes Table of Contents in Jupyter notebooks are not clickable due to some technical issues. So it would be nice if your Table of Contents is clickable, but this is not a requirement.
10. You need to include your source code in your reports. We cannot mark any project reports missing the source code. In addi!on, you will not get any credits for computer code that you do not execute: you will need to show us the output of your code.
11. Submissions are to be made via Canvas by the due date and !me.
12. Please see Course Policies for late report submission penal"es.
13. If you make mul!ple submissions, only the most recent one shall be marked all the previous submissions will be discarded.
Group Selection Instructions
1. For the course project, you can work alone or you can work in groups of 2 or 3 students (and no more). If you have at least 2 members in your group, then only one of the members must make the submission.
2. Due to some technical issues with Canvas, even if you are working alone, you must s"ll sign up for a group (which will obviously have only one member). If you don't, your project mark may show up as zero in the system even if you make a personal project submission due to Canvas so#ware glitches.
3. In order to sign up for groups, please follow the instruc!ons below:
1. Go to the "People" link on the le$ panel on Canvas. This link will be made visible no later than the end of Week 2.
2. Click on the "Course Project Groups" tab. You will see bunch of groups in there.
3. Star"ng from the top, please pick the first empty group number for your group.
4. You can sign up to any group yourself without permission from course staff. You can also move between groups as many !mes as you want before the due date for finalising group membership.
5. If you are joining a non-empty group, you must have the consent of the exis"ng group member(s) before you sign up.
6. The due date for finalising your group members will be end of Week 4. Beyond this date, group membership cannot be changed. This is to avoid dramas due to last-minute group changes.
7. All group members shall receive the same mark. Any serious disagreement among team members should be reported to the Course Coordinator and such disagreements shall be dealt with on a case-by-case basis.
Plotting Requirements for Phase 1
The minimum number of different plots you need to include in your Phase 1 report for the data explora"on & visualisa"on part as follows:
A group of 1 member: at least 2 plots of each one of the following: one-variable plots, two-variable plots, and three-variable plots (that is, minimum 2*3=6 plots in total)
A group of 2 members: at least 3 plots of each one of the following: one-variable plots, two-variable plots, and three-variable plots (that is, minimum 3*3=9 plots in total)
A group of 3 members: at least 4 plots of each one of the following: one-variable plots, two-variable plots, and three-variable plots (that is, minimum 4*3=12 plots in total)
Addi!onal plo%ng instruc!ons are as follows:
1. For plo%ng, you are free to use whatever Python module you like: Matplotlib, Seaborn, Altair, Plotly, etc.
2. Your plots must be meaningful and they need to make sense with respect to the goals and objec!ves of your project.
3. As long as your plots are meaningful and relevant, there are no restric!ons on the plot types. That is, you can have a mix of box-plots, histograms, line plots, sca#er plots etc.
4. For each plot in your report, you will need to label the x- and y-axes as appropriate and also add a meaningful title.
Algorithm Requirements for Phase 2
The minimum number of different ML algorithms you need to try on your problem in your Phase 2 report are as follows:
A group of 1 member: at least 3 algorithms
A group of 2 members: at least 4 algorithms
A group of 3 members: at least 5 algorithms
As far as this course project is concerned, the criteria for a "different algorithm" is that you need to import a different Scikit-Learn sub-module for it. For instance, decision trees and random forests are different algorithms. On the other hand, 1-KNN and 3-KNN are the same algorithm (just with different hyper-parameter values). Another remark is that there are no hard requirements for your modelling methodology as long as it makes sense and it is consistent with ML best prac!ces. For instance, using a pipeline is not a requirement.
Addi"onal Algorithm Requirements for Advanced Submission Mode:
In addi!on to the requirements above, you need to include a detailed neural network (NN) modeling sec!on for your problem in your Phase 2 report as explained in the relevant Assessment Criteria sec!on below.
Group Collaboration Tools
Try Google Colab. It has some collabora!on tools (for example, you can add comments for other members to see). For sign-up, your RMIT email should work fine.
Try opening a private repository on GitHub and invite your group members. You can check in/ check out files, do version controlling etc. This should be free up to groups of three.
Phase 1 Assessment Criteria (100 points in total)
REQUIREMENT: The green-highlighted texts below must be the Sec"on headers in your Phase 1 report.
(Task 0.1) (2 points) Please give your project a proper !tle. Example: "Predic!ng Melbourne House Prices" etc.
(Task 0.2) (5 points) Please include a proper Table of Contents.
(Task 1) (28 points total) Introduc"on: This sec!on needs to include the following subsec!ons:
(Task 1.1) (3 points) Dataset Source: Please explain your data source properly and provide a proper cita!on in a References sec!on at the end of your report.
(Task 1.2) (5 points) Dataset Details: Explain in sufficient detail what the dataset is about. Also please report the number of observa!ons (rows) and the number of features (columns) in your dataset. And please print 10 random observa"ons (rows) from your dataset. Please make sure we can see all the columns by adding this code in your report:
import pandas as pd
pd.set_option('display.max_columns', None)
(Task 1.3) (18 points) Dataset Features: Explain the features in your dataset that you will be including in your project in a table format. To be clear, please include only the features you will use in your project and leave out the ones you will not be using in your project. In your table, you need to have one feature per row with the following 4 columns:
1. Name of the feature
2. Data type (numeric, binary, nominal categorical, ordinal categorical, date)
3. Units ("Unknown" or "NA" for Not Applicable are acceptable)
4. Brief descrip!on
(Task 1.4) (2 points) Target Feature: This is really important: you need to clearly iden!fy your target feature. That is, what is it that you will be predic!ng in your Phase 2 report? Also state if it is a numerical or categorical feature.
(Task 2) (7 points) Goals & Objec"ves for modelling this par!cular data.
(Task 3) (15 points) Data Cleaning & Preprocessing as appropriate (dealing with missing values & outliers & incorrect values (such as nega!ve age), dropping ID-like columns, data aggrega!on if necessary etc). If your dataset is already clean and ready for modelling, you will get the full score for this task, our treat! For this section, you will need to add subsec!ons as appropriate for be#er organisa!on of your work.
Task 3 Clarifica"on #1: Please do not perform any one-hot-encoding or scaling in Phase 1. Thank you.
Task 3 Clarifica"on #2: For this task, sampling is op"onal: you can perform sampling (for a smaller dataset for ease of computa!on) either in Phase 1 or Phase 2, or you may choose to skip sampling all together if you like.
(Task 4) (15 points) Data Explora"on & Visualisa"on as appropriate with proper explana!on: charts, graphs, boxplots, numerical summaries, etc. For this sec!on, you will need to add subsections as appropriate for be#er organisa!on.
(Task 4.5) (Advanced Submission Mode Only, 15 points) Literature Review This sec!on needs to report and explain exis!ng closely-related research studies in the par!cular field of your project. Please make sure you include some recent references published in the last few years. This sec!on needs to include a minimum of 10 journal ar"cles and a minimum of 4 conference papers in a dedicated References sec!on at the end of your report (with correct APA cita!on style). In addi!on, this sec!on needs to be at least 600 words excluding the references.
Task 4.5 Clarifica"on #1: For this task, 8 points will be allocated to the comprehensiveness and accuracy of your literature review itself. The remaining 7 points will be allocated to the correctness & appropriateness of your references.
Task 4.5 Clarifica"on #2: Links to some websites do not count as a journal ar!cle or a conference paper reference!
Example of a journal ar"cle & its reference:
Yum, H., Lee, B., and Chae, M. (2012). From the wisdom of crowds to my own judgment in microfinance through online peer-to-peer lending pla'orms. Electronic Commerce Research and Applica!ons, Vol 11, pp. 469–483.
Example of a conference paper & its reference:
Backstrom, L., Hu#enlocher, D., Kleinberg, J., and Lan, X. (2006). Group forma!on in large social networks: Membership, growth, and evolu!on. In 12th ACM Interna!onal Conference on Knowledge Discovery and Data Mining, pp. 44–54.
(Task 5) (10 points) Summary & Conclusions of the first phase of your project: a comprehensive summary of Phase 1 and any insights you gained in this phase as they relate to your goals and objec!ves.
(Task 6) (REQUIRED, 3 points) References For ci!ng any book, ar!cle, paper, website, etc. in your report, you need to use the APA style.
Phase 2 Assessment Criteria (100 points in total)
REQUIREMENT: The green-highlighted texts below must be the Sec"on/ Subsec"on headers in your Phase 2 report.
(Task 0) (5 points) Please include a proper Table of Contents.
(Task 1) (15 points total) Introduc"on: This sec!on needs to include the following subsec!ons:
(Task 1.1) (5 points) Phase 1 Summary: A brief yet complete and accurate summary of the work conducted for your Phase 1 report and how they relate to your Phase 2 report.
(Task 1.2) (5 points) Report Overview: A complete and accurate overview of the contents of your Phase 2 report. Clarifica"on: A Table of Contents is not a report overview.
(Task 1.3) (5 points) Overview of Methodology: A detailed, complete, and accurate overview of your predictive modelling methodology.
(Task 2) (55 points total) Predic"ve Modelling: This sec!on needs to include the following subsec!ons:
(Task 2.1) (10 points) Feature Selec"on (FS) as appropriate. We would like to see some meaningful effort for selec!ng the best descrip!ve features in your dataset and some meaningful plots. For FS, there are no hard requirements; you can use any FS method and any number of features you like. However, you need to try at least one FS method and at least one specific number of features. For example, you can simply select 10 features using f_classif for classification problems or f_regression for regression problems.
(Task 2.2) (25 points) Model Fi!ng & Tuning: Details of your ML algorithms’ fine-tuning process and performance analysis of each algorithm. You will also need to include at least one (meaningful) plot showing the results of your hyper-parameter fine-tuning process for each one of your algorithms.
(Task 2.2.5) (15 points for Advanced Submissions) Neural Network Model Fi!ng & Tuning: You will need to include a proper NN modelling discussion section with at least 600 words that provides an accurate, detailed, and insigh'ul overview of your NN model including the topology and all the relevant model parameter values you used (7 points). In addi!on, you will need to fine-tune at least 5 different NN hyperparameters and present at least 5 different fine-tuning plots with proper narra!ve and sufficient explana!on (8 points). For NN models, you will find the link here on our website useful.
(Task 2.3) (5 points) Model Comparison of the algorithms' performance as appropriate (cross-valida!on, AUC, etc.) using paired t-tests.
NOTE: For Task #2 (Predic!ve Modelling), your work will be marked on correctness of your methodology, not absolute performance of your models. For instance, you will not lose points if your results indicate a poor performance, but you will need to discuss this in the Cri!que & Limita!ons sec!on of your report.
(Task 3) (10 points) Cri"que & Limita"ons of your approach: strengths and weaknesses in detail.
(Task 4) (15 points total) Summary & Conclusions: This sec!on needs to include the following subsec!ons:
(Task 4.1) (5 points) Project Summary: A comprehensive summary of your en"re project (both Phase 1 and Phase 2). That is, what exactly did you do in your project? (Example: I first cleaned the data in such and such ways. And then I applied such and such algorithms with such metric. Next I performed paired t-tests to identify the sta!s!cally best performing algorithm etc).
(Task 4.2) (5 points) Summary of Findings: A comprehensive summary of your findings. That is, what exactly did you find about your par!cular problem?
(Task 4.3) (5 points) Conclusions: Your detailed conclusions as they relate to your goals and objectives.
CLARIFICATION #1 ON ASSESSMENT CRITERIA: The above assessment criteria only apply to "proper" project submissions. If your submission is fundamentally flawed, you may receive a mark of zero regardless of whatever else is in your report. For instance, if you
Fail to disclose the source of your dataset or
Use a blacklisted dataset
you will not get any credits for your project.
CLARIFICATION #2 ON ASSESSMENT CRITERIA: In case of the following mistakes, you will automatically loose the entire points corresponding to the Predictive Modelling, Critique & Limitations, and Summary & Conclusions sections:
Your report does not contain any predic!ve modelling procedures.
Your project uses !me-series data wherein the rows in your dataset are correlated. Why? Because a fundamental assump!on in machine learning in general is that the observa!ons in your dataset are random samples from the en!re popula!on of observa!ons.
You use an ID-like variable in your model. Remember, ID-like variables that have a unique value for each row (such as customer ID, pa!ent ID, record no, student ID, etc) must be removed during the data pre-processing step before fi%ng any models. Why? Because including an ID-like variable in an ML model is such a huge mistake that it will render all your results meaningless.