Hello, if you have any need, please feel free to consult us, this is my wechat: wx91due
Economics 3210
Summer 2025
Assignment #1: Simple Regression
Upload your answers to Canvas. Write out your answers by hand. Then scan to pdf and upload them to Canvas. Use the following naming convention:
Lastname_firstname_netid_ECON3120_Assignment1.pdf
You may combine your scans into a word document if you like. Then convert that document to pdf. Do NOT send high-res photos. Those files are too big. Check your file to be sure that we can read it. No links to Google drives. No links to Google docs. (You get the idea…)
A note on computing: Given the short time for the summer course, I’ll provide you outputs rather than ask you to run jobs. If you wish to gain some experience with Stata you may do it along with the Fall version of the course. I’ll add you to the Canvas site for that course.
The computer part of this problem set involves running two programs. The first estimates a simple regression explaining the percentage change in stock prices on the day earnings per share was announced as a function of the gap between actual earnings per share and expected earnings per share. The second estimates several simple regressions explaining labor force participation rates and durations of spells of unemployment. You may use the outputs I supply rather than running your own jobs.
PART 1 (OPTIONAL): Running and Interpreting your own job
Some years ago the New York Times published an article about the track record of securities analysts in predicting earnings per share. Expected future earnings are the main determinant of stock prices. This means that if analysts forecast a company's earnings poorly (i.e., if they significantly overestimate or underestimate its earnings), then when actual earnings are announced, the stock price may move substantially.
The relationship between movement in the price of a stock and the extent to which the stock market is “surprised” by actual earnings may be formulated as the simple regression
(1) PCHPERi = β0 + β 1GAPi + ui
where
PCHPERi = percentage change in the price of stock i on the day actual earnings were announced, i.e., 100x(closing price - opening price)/opening price
GAPi = percentage amount by which expected earnings per share differed from actual earnings per share, i.e., 100x(expected EPS - actual EPS)/actual EPS
The data in the New York Times article allow these variables to be calculated. For each of the 10 observations reported there, the article cited expected earnings per share (EPSE), actual earnings per share (EPSA), the change in the stock's price the day earnings were announced (PCH), and the stock's closing price (PCLOSE). The stock's opening price (POPEN) is the closing price minus the change in price. The data appear below.
|
EPSE |
EPSA |
PCH |
PCLOSE |
|
.21 |
.54 |
-1.69 |
21.75 |
|
.28 |
.35 |
3.13 |
27.75 |
|
.08 |
.11 |
2.13 |
13.75 |
|
.13 |
.05 |
-4.63 |
23.88 |
|
.20 |
.28 |
2.13 |
21.25 |
|
1.12 |
.82 |
-12.38 |
59.13 |
|
.94 |
1.11 |
1.13 |
43.88 |
|
1.27 |
1.13 |
-1.50 |
54.50 |
|
.21 |
.04 |
-12.38 |
8.75 |
|
.61 |
.54 |
-.50 |
35.75 |
You may either enter the data directly into Stata, or create an Excel spreadsheet and then read the Excel spreadsheet into Stata. In addition to those variables, I want you to create the following variables (in either Stata or in Excel first, as you wish):
POPEN = PCLOSE – PCH
PCHPER = 100*(PCLOSE-POPEN)/POPEN
GAP = 100*(EPSE-EPSA)/EPSA
Now run the simple regression of PCHPER onto GAP [equation (1) above].
1. Consider the estimate of (1).
a. Interpret β1 . Does this value seem to be consistent with the hypothesis that markets are "efficient," i.e., that they respond rapidly to new information?
b. What is R2? Does this value seem to support the hypothesis in question?
(Note: Later in the course we will be able to test these hypotheses formally. At this point you are being asked for your informal assessments.)
PART 2: Labor Force Data
The second part of your computer work involves analyzing labor force data. Copy the Stata dataset lfp.dta to wherever you are using Stata. The file contains the following variables for the U.S. from 1948-1994 (annual data):
LFPt = civilian labor force participation rate in year t (percentage points)
LFPMt = male civilian labor force participation rate in year t (percentage points)
LFPFt = female civilian labor force participation rate in year t (percentage points)
URt = unemployment rate among civilian workers in year t (percentage points)
AVGDURt = mean duration of a spell of unemployment in year t (weeks)
MEDDURt = median duration of a spell of unemployment in year t (weeks)
TIMEt = 1 in 1948, 2 in 1949, ..., 47 in 1994
I computed the (natural) logarithm of the male and female LFP’s, for you. Call those variables LOGLFP, LOGLFPM, and LOGLFPF, corresponding to the total, male, and female labor force participation rates, respectively.
The questions that follow refer to regression equations, numbered in parentheses, e.g. (2). Estimate those equations using Stata, and use the output to answer the questions.
2. Consider the estimates of the following models:
(2) LFPt = β0 + β1URt + ut
(3) LFPFt = β0 + β1URt + ut
a. Interpret β1 from (2), including its units. Compare to β1 from (3). Are the signs and magnitudes of these coefficients consistent with the hypothesis that high unemployment rates lead to discouraged workers exiting from the labor force?
b. For (2), what are the values of SSE, SSR, and SST (error sum of squares, regression sum of squares, and total sum of squares)?
d. What is R2 for (2)? Interpret this value.
e. Can we compare how well (2) and (3) "fit" by comparing their R2's? Why or why not?
3. Consider the estimates of the following models:
(4) AVGDURt = β0 + β1URt + ut
(5) MEDDURt = β0 + β1URt + ut
Note that MEDDUR is available only from 1968 on.
a. Interpret β1 from (4), including units.
b. Is the mean (average) duration of a spell of unemployment or the median duration of a spell of unemployment estimated to be more sensitive to the unemployment rate? Explain the reasoning behind your answer.
c. Verify that the estimated regression line for (4) passes through the “point of means”
(UR , AVGDUR) .
d. Note that in every year, MEDDUR < AVGDUR. What does this suggest about the shape of the
distribution of duration of unemployment spells in any one year? Why might the difference between median duration and average duration be of interest to policy-makers?
4. Consider the estimates of the following models:
(6) LFPFt = β0 + β1TIMEt + ut
(7) LFPMt = β0 + β1TIMEt + ut
(8) LOGLFPFt = β0 + β1TIMEt + ut
(9) LOGLFPMt = β0 + β1TIMEt + ut
a. Interpret β1 from (6) and (7), including units. Can you think of an explanation for the opposite trends in these two dependent variables?
b. Interpret β1 from (8) and (9), including units.
c. Can we compare how well (6) and (8) “fit” by comparing their R2's? Why or why not?
5. Consider the regression ofthe unemployment rate on TIME:
(10) URt = β0 + β1TIMEt + ut
a. Interpret β1 Does the value of β1 suggest that the natural rate of unemployment has experienced a trend? Explain.
b. Suppose we define a new variable YEAR, where YEARt = TIMEt + 1947, and consider the regression ofthe unemployment rate on YEAR:
(11) URt = β0 + β1YEARt + ut
Without actually estimating (11) give the values that we would get for β0, β1 , and R2.
PART 3: Analytic Exercises
6. In the model you estimated above
(4) AVGDUR = β0 + β 1UR + u
the explanatory variable was in percentage points, and the dependent variable was in weeks.
a. Suppose we were to change the units ofUR so that UR gives the fraction of the labor force that
was unemployed (i.e., we divide UR by 100). How will this change affect β1? Will this affect
β0 and R2 and if so, how? Justify your answers.
b. Suppose instead we were to change the units of AVGDUR so that AVGDUR gives the mean
duration of a spell of unemployment in days (i.e., we multiply AVGDUR by 7). Will this affect β0, β1, and R2 and if so, how? Justify your answers
Part 4: Harder Analytics
7. Explain what happens to the ability of least squares to estimate β0 and β 1 of a simple regression model when all values of X in the sample are the same? If (instead) all values of Y in the sample are the same? (You may want to draw a picture to help you think about this.)
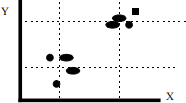
8. (Optional: interesting, but hard.) Suppose you have a set of data on Y and X whose scatter plot
consists of two "clumps," as depicted below. You wish to estimate β 1 of the simple regression model Yi = β0 + β 1Xi + ui. Consider the following alternative to the least squares estimator ![]() 1:
1:
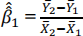
where the subscripts 1 and 2 on the means refer to the two “clumps” of data. Subscript 2 refers to the clump with larger values. That is, find the point of means for each “clump” and then draw a line between those two points.
a. Will ![]() 1 =
1 = ![]() 1 (except by chance)? Explain intuitively why not.
1 (except by chance)? Explain intuitively why not.
b. Consider the second “clump” of observations. Imagine increasing the sample
variance of Y among these observations (making them more spread out vertically), keeping Y2 the same. Will this affect the value of β1 ? What about the least squares estimator β1? Explain.
9. (Required) Show that if one regresses y onto a constant only the resulting β0 is exactly the sample mean of y. (Hint: set up and solve the least squares problem.)
10. (Optional: interesting, but hard.) Consider the relationship between two variables, X and Y. We have n observations on X and Y. Define the concept of the standard deviation (SD) line: This is the line passing through the “point of means”, (X, Y), with slope sY/sX (the ratio of the standard deviations of Y and X) if X and Y are positively correlated, and with slope (-sY/sX ) if X and Y are negatively correlated.
a. For the simple regression model Yi = β0 + β 1Xi + ui, write the least squares slope
estimator β1, as a function of rXY (the simple correlation between X and Y) and sx and sY.
b. Assuming 0 < rXY < 1, what will be the position of the estimated regression line relative to the position of the SD line? What is the reason behind this relative position?
c. How will this relative position change as rXY increases from 0 to 1?
d. Sir Francis Galton (1822-1911) coined the term “regression” in a study of the relationship
between heights of sons and heights of their fathers. He observed that although tall fathers had tall sons, and short fathers had short sons, there was a tendency for sons’ heights to converge toward the mean. In other words, a taller-than-average father usually had a taller-than-average son, but the son tended not be as far above the average as his father. This is “regression toward the mean.”
Consider the simple regression model, where Xi is height of father i, and Yi is height of his son. In a sample of fathers and sons, X- = 68 inches, Y- = 69 inches, sX = sY = 2.7 inches, and rXY = .5.
Will Galton’s “regression” be evident in this sample? Explain.
e. A preschool program attempts to boost children’s IQs. Children are tested when they enter the program (the pre-test) and when they leave (the post-test). On both occasions, the mean score is 100, with standard deviation 15. But a closer look shows that children who were below average on the pre-test had an average gain of about 5 points on the post-test, while children who were above average on the pre-test had an average loss of 5 points on the post-test.
Should the program worry that their curriculum tends to equalize IQs rather than boost them? Why or why not? (Hint: Why is this phenomenon similar to the regression of sons’ heights toward the mean?)
f. Is it possible to compute β1 in the regression model of post-test scores on pre-test scores from the available information?
Part 5: Real Life Statistics
11. People who are arrested and charged with crimes are held in jail until trial, unless they can post bail or they are released on their own recognizance (ORed) by the court. (ORed means that the person does not post bail, but just promises to appear for trial.) One study showed that in 1960, over 50% of all those charged with a crime in New York were held in jail until trial. And those detained were two or three times as likely to be convicted or imprisoned as those released, even after controlling for family background and type of crime.
(a) Does this show that being detained increased the likelihood of conviction or imprisonment? If not, what is an alternative explanation?
In the same year, the Vera Foundation initiated a randomized controlled experiment on bail procedures. The foundation selected a group of a thousand people who were detained pending trial. These were mainly indigents who could not raise bail but who were eligible for OR according to the foundation’s criteria, mainly for having roots in the community such as a family or a job; persons accused of serious crimes were automatically excluded. The foundation chose five hundred out of these thousand people at random for the treatment group, and the other five hundred from the control group. For those in the treatment group, the foundation wrote letters to the court, recommending OR and giving some facts on family background and job history. In the treatment group, about 60% were ORed, compared to 15% in the control group.
(b) Does this show that treatment increased the likelihood of parole? Explain.
Of those ORed in the treatment group, only 40% were convicted at their trial. On the other hand, of those detained in the control group, about 80% were convicted.
(c) Is this a fair comparison to measure the effect of the letter on the likelihood of conviction, or should Vera have compared the parolees with the parolees, and those detained with those detained? Explain.
From 1961 to 1964, the Vera Foundation continued the experiment, but without controls. About 2,000 were ORed on Vera recommendations during this period, and only 15 failed to show up for trial, a default rate well under 1%. In fact, the main point of the experiment was to prove that poor people could be released on their own recognizance, without posting bail, and would still show up for trial. City officials were convinced, and the Vera program was institutionalized as a regular part of the New York court system.
(d) Would the default rate be expected to go up, go down, or stay about the same after the experimental phase was over? Explain.