COMP2511 / 24T1 / specs / assignment-iii-spec · GitLab
Assignment III: Tributary
Due Week 10 Friday, 5pm Sydney Local Time (19th April 2024)
What is this assignment aiming to achieve?
Having completed Assignments I and II, and gained familiarity and experience with course concepts, itʼs time to turn this into expertise. This assignment aims to get you working on an important problem in modern software architecture - event-streaming and event pipelines.
Since this is a bonus assignment, its completion is not required to get 100% in the course. That said, the assignment aims to provide high-achieving students with an opportunity to practice with the following 4 points:
1. Synthesising Complex and Abstract Requirements. This problem is a bit different from those youʼve encountered before, and may be difficult to understand at first. However, once you understand what youʼre working with, the solution is more straightforward than coming to your initial understanding.
2. Building a Java API. Using your skills in Design by Contract, youʼll need to design a library that could be used to build event-driven systems.
3. Design and Testing Methodologies. Youʼll be completing a preliminary design to set the trajectory before diving in, and iterating on your design as you go. Youʼll also be planning out and writing a test suite for the system.
4. Event-Driven & Asynchronous Design. In developing this system, youʼll learn about how event streaming works and how event-driven design can be used in software systems. Youʼll also need to consider the implications of working asynchronously, and how to manage concurrency issues.
1. Getting Setup
This assignment can be completed in pairs or individually. You will be marked differently depending on whether you complete the assignment as a pair or individually. You can continue with the same pair as you had in Assignment II, or form a new pair if you like.
Please notify your tutor of your preference to work in a pair or individually by Week 10 Monday. You will not be able to change preferences after this date.
2. Overview
Event-Driven Architecture makes up much of the backbone of modern software. With a move towards decentralised microservice systems, there is a need for scalable asynchronous communication between software components.
In this assignment you will use principles discussed in lectures to write a Java API that another engineer could use to build an event-driven system.
This library is based on a heavily simplified version of the event streaming infrastructure Apache Kafka, which you can read more about for your own interest. No understanding of Kafka is required to complete this assignment
2.1. Introduction Video
NOTE: This video makes references to an older version of the spec, but the core concepts are the same.
3. Engineering Requirements
The fundamental premise on which Event-Driven Architecture rests is the ability of producer and consumer entities in the system to share data asynchronously via a stream-like channel.
However, our library will allow for more complex interactions than simply that of a single channel.
A Tributary Cluster contains a series of topics. A topic contains events which are logically grouped together. For example, a cluster could contain two topics: one for images-related events and one for video-related events. You can think of them like a table in a database or a folder in a file system.
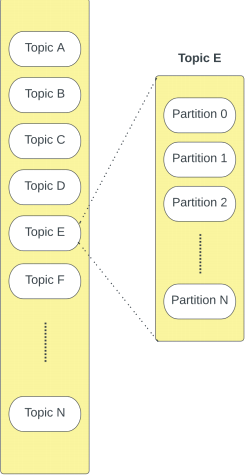
Within each topic, there are a series of partitions - each partition is a queue where new messages are appended at the end of the partition.
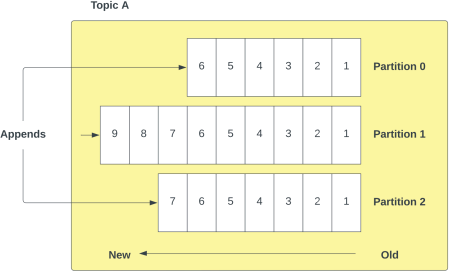
A unit of data within a Tributary is a message, or record or event. For example, to update their profile a user may send a message to Partition 1 in Topic A, and this message will be appended to Partition 1 in Topic A. Each message has an optional key to indicate which partition it should be appended to.
A topic can be related to “user profilesˮ and each message relates to requesting an update to a specific profile. However, considering there can be many such requests at a given time, the system divides the incoming requests into multiple partitions. There can be multiple consumers consuming messages at the same time (concurrently). However, each partition is handled by only one consumer. Multiple consumers will allow us to effectively utilise the underlying hardware with multiple cores.
In the context of the library you are building, topics are parameterised on a generic type; all event payloads within that topic must be of the specified type.
3.1. Message Lifecycle: A Simple Example
Let us take the example of a user updating their profile. This results in an event being generated by the producer for a topic “user profilesˮ with the updated profile information. This event is now delivered to the Tributary, which assigns the event to one of the partitions. The producer indicates whether the message is randomly allocated to a partition, or provides a key specifying which partition to append the message to.
A consumer processes one or more partitions by sequentially processing (consuming) events in the allocated partitions.
3.2. Message Structure
Individual messages contain the following information:
Headers
Datetime created;
ID;
Payload type;
Key; and
Value. The value is an object containing relevant information for a topic. Considering information required for different topics may change, you should consider using a generic type here
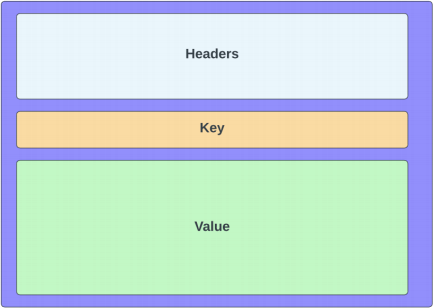
3.3. Producers
A Producer is responsible for sending messages to the Tributary system. As shown in the diagram above, a message contains info including the datetime it was created, the source producer, etc. Messages may have a key which indicates the specific partition to send the message to. Alternatively, messages are randomly assigned to a partition by the system.
3.3.1. Allocation of Messages to Partitions
Producers can indicate whether to send a message to a particular partition by providing the corresponding partition key or requesting random allocation. There are two types of producers:
Random Producers - the producer requests the Tributary system to randomly assign a message to a partition
Manual Producers - the producer requests the Tributary system to assign a message to a particular partition by providing its corresponding key.
Once a producer has been created with one of the two above message allocation methods, it cannot change its message allocation method. Your implementation should allow for producers to be created with new message allocation methods added in the future.
3.4. Consumer and Consumer Groups
3.4.1. Consumers
Consumers are responsible for consuming (processing) messages stored in partition queues. A consumer consumes messages from a partition in the order that they were produced, and keeps track of the messages that have been consumed. Although each partition can be consumed by only one consumer, each consumer can consume from more than one partition. Consumers operate as part of a consumer group.
3.4.2. Consumer Groups
A consumer group consists of one or more consumers, that are together capable of consuming from all the partitions in a topic.
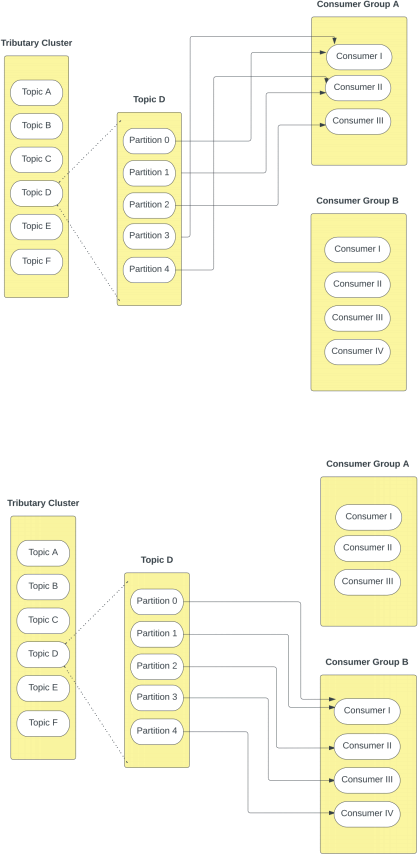
Each topic can have multiple consumer groups. While each consumer group assigned to the same topic may contain a different number of consumers, they will all consume from the same number of partitions, i.e. all the partitions in a topic will always be handled by any consumer group assigned to the topic.
When a new consumer group is created, the consumers in the group begin their consumption from the first unconsumed message in all of the topics partitions they are assigned to. In other words, all consumers that share a partition consume messages parallel to each other, so that each message is only consumed once (except in controlled replays).
For example, in the image below Topic D is consumed by Consumer Group A, which has its 3 consumers assigned to the 5 partitions. Topic D is also consumed by Consumer Group B, which has its 4 consumers assigned to the 5 partitions.
3.4.3. Consumer Rebalancing
A system should be able to dynamically change the rebalancing strategy between one of two rebalancing strategies - range rebalancing, and round robin rebalancing. These rebalancing strategies are used to reassign partitions to consumers anytime a consumer is added to a consumer group or an existing consumer is removed from a consumer group.
If a partition is assigned a new consumer after rebalancing, the new consumer should continue consumption from where the previous consumer left off.
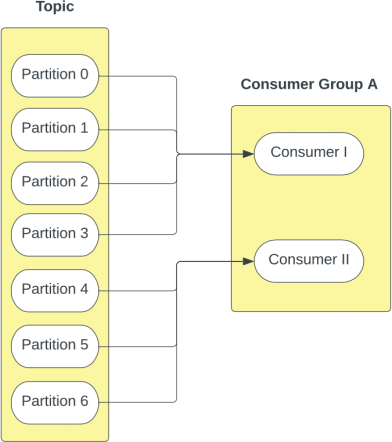
In the above example, Partitions 0, 1, 2, 3 are allocated to Consumer I and Partitions 4, 5 and 6 are allocated to Consumer II.
3.4.3.2. Round Robin Rebalancing
Round Robin - In a round robin fashion, the partitions are allocated like cards being dealt out, where consumers take turns being allocated the next partition.
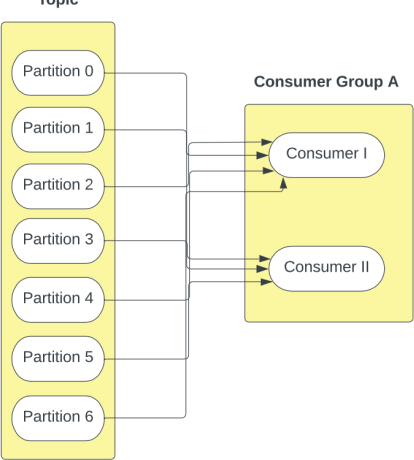
In the above example, Partitions 0, 2, 4 and 6 are allocated to Consumer I, and Partitions 1, 3 and 5 are allocated to Consumer II.
3.5. Replay Messages
One of the most powerful aspects of event streaming is the ability to replay messages that are stored in the queue. The way this can occur is via a controlled replay, which is done from a message offset in a partition. Messages from that point onwards are streamed through the pipeline, until the most recent message at the latest offset is reached.
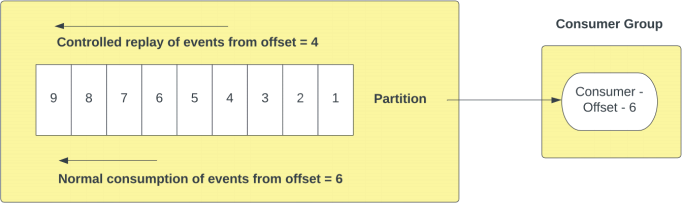
NOTE: The above image demonstrates a consumer starting at offset 6 that performed normal consumption until offset 9. This consumer then triggered a controlled replay from offset 4 that played back all the messages from that offset until the most recently consumed message (i.e messages 6, 7, 8 and 9 were consumed again).
3.6. Design Considerations
Two design considerations you will need to think about in your solution are as follows:
Concurrency - since Producers and Consumers are all running in parallel, operating on a shared resource, how will you ensure correctness?
Generics - How will you ensure that an object of any type can be used as an event payload in a tributary topic?
One of the key aims of this assignment is to get accustomed with concurrency in Java using the synchronized keyword as shown in lectures. As such we will not be permitting the use of any existing synchronization and concurrency libraries as you must implement thread-safety yourselves.
This includes but is not limited to:
The entire java.util.concurrent package
This includes any classes or interfaces that require this import namely thread-safe objects (eg AtomicInteger ) or concurrency primitives (eg semaphores).
Any other thread-safe classes such as StringBuffer