CS 274A: Homework 3
Probabilistic Learning: Theory and Algorithms, CS 274A, Winter 2024
Due: 12 noon Wednesday February 7th, submit via Gradescope
Instructions and Guidelines for Homeworks
• Please answer all of the questions and submit your solutions to Gradescope (either hand-written or typed are fine as long as the writing is legible).
• All problems are worth equal points (10 points) unless otherwise stated. All homeworks will get equal weight in computation of the final grade for the class (with lowest-scoring homework being dropped).
• The homeworks are intended to help you better understand the concepts we discuss in class. It is important that you solve the problems yourself to help you learn and reinforce the material from class. If you don’t do the homeworks you will likely have difficulty in the exams later in the quarter.
• In problems that ask you to derive or prove a result you should submit a complete mathematical proof (i.e., each line must follow logically from the preceding one, without “hand-waving”). Be as clear as possible in explaining your notation and in stating your reasoning as you go from line to line.
• If you can’t solve a problem, you can discuss the high-level concepts verbally with another student (e.g., what concepts from the lectures or notes or text are relevant to a problem). However, you should not discuss any of the details of a solution with another student. In particular, do not look at (or show to any other student) any written material directly related to the homeworks, including other students’ solutions or drafts of solutions, solutions from previous versions of this class, etc. The work you hand in should be your own original work.
• If you need to you can look up standard results/definition/identities from textbooks, class notes, text books, other reference material (e.g., from the Web). If you base any part of your solution on material that we did not discuss in class, or is not in the class notes, or is not a standard known result, then you may want to rovide a reference in terms of where the result is from, e.g., “based on material in Section 2.2 in .....” or a URL (e.g., Wikipedia).
Recommended Reading for Homework 3: Note Set 4 on Bayesian Learning. Chapter 4.6 in Murphy Book 1 is optional additional reading for more detail on Bayesian methods, but its not necessary to read this to be able to do the homework.
Problem 1: Beta-Binomial Model
Consider the binomial likelihood model with a beta prior as we discussed in class. Let the number of successes in the data be r out of n trials. Say the true unknown value of θ = 0.8. Consider the following 2 data sets:
1. r = 3, n = 3;
2. r = 36, n = 50;
Consider also two possible sets of priors:
1. α = β = 1
2. α = β = 10.
- Generate 2 × 2 = 4 plots on a single page, where each row corresponds to each of the 2 data sets and each column corresponds to the two priors. Plot the prior and the posterior densities for each case over the range θ ∈ [0, 1]. Mark on the x-axis on your plot where the true value of θ = 0.8 is located as well as the location of the maximum likelihood estimate. Clearly indicate on your plot what the different curves and marks correspond to. Also comment briefly on what you observe from these plots (a few sentences are fine).
- A posterior credible interval in Bayesian analysis can be defined as a range for θ that contains most of the posterior probability mass. For example we could define a 95% posterior credible interval as the range θ corresponding to the region between θ ∈ [θl , θu] where θl and θu are defined as values to the left and right of which (respectively) are 2.5% of the “tail” probability mass. Using this definition of a credible interval, for each of the 4 combinations of priors and datasets determine what the values of θl and θu are in terms of defining a 95% posterior credible interval (no need to plot this, just state what this interval is for each of the 4 cases). Feel free to use whatever method you wish to determine θl and θu. Your answer should be accurate to within two decimal places.
You should generate your plots and credible intervals on a computer (rather than hand-drawn, etc), using whatever language you wish, but no need to submit any code.Homework 3: CS 274A, Probabilistic Learning: Winter 2024
Problem 2: Bayesian Estimation for the Multinomial Model
Consider a data set D = {x1, . . . , xN }, with xi ∈ {1, . . . , K} where the xi’s are conditionally independent draws from a discrete-valued distribution with parameters θk = P(xi = k), 1 ≤ k ≤ K, and P K k=1 θk = 1 (i.e., we have a multinomial likelihood for the xi’s). Assume that we have a Dirichlet prior for the parameters θ, where the prior has parameters α1, . . . , αK and αk > 0 and 1 ≤ k ≤ K.
- Prove that the posterior distribution on θ1, . . . , θK is also Dirichlet and find it’s parameters.
- Derive an expression for the maximum a posteriori (MAP) estimate for θk, 1 ≤ k ≤ K. Your solution should be derived from first principles (i.e. using basic calculus to find the mode of the posterior density for θk, working from your solution for P(θ|D) from part 1).
Problem 3: Bayesian Estimation for the Geometric Model
Let X be a geometric random variable taking values x ∈ {0, 1, 2, . . .}, with probability distribution defined as
P(x) = (1 − θ)
x
θ, for x = 0, 1, 2, . . . (1)
where θ is the parameter of the geometric model and 0 < θ < 1. The geometric distribution models a problem where we have a sequence of random binary outcomes with “success” probability θ, where the outcomes are generated independently at each step, and x is the number of steps before success. For example this could be a model of the number of tails we see in tossing a coin before we see heads, where θ is the probability of heads.
Let D = {x1, . . . , xN } be an observed data set where we assume the samples were generated in an IID manner from P(x).
- Define the likelihood function for this problem.
- Prove that the Beta density Be(α, β) is a conjugate prior for the Geometric likelihood and derive an equation for the posterior density for θ. (A prior is said to be conjugate to a particular type of likelihood function whenever the posterior has the same functional form (the same type of density) as the prior).
Problem 4: Bayesian Estimation for the Mean of a Gaussian Model
Consider a data set D = {x1, . . . , xN }, with real-valued scalar xi values. Assume that the xi’s are conditionally independent draws from a Gaussian density with unknown mean µ and known variance σ
2
. Assume we have a Gaussian prior on µ that has mean µ0 and variance s
2
. Given the facts above, derive the following expressions from first principles, clearly explaining and justifying all of your steps:
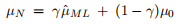
and
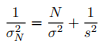
where µN and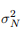 are the mean and variance of the posterior density for µ and
are the mean and variance of the posterior density for µ and
are the mean and variance of the posterior density for µ and
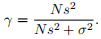
Problem 5:
Consider a random variable X taking integer values x ∈ {0, 1, 2, . . .}. These could for example be countsof the number of times a particular type of event occurs per hour. Assume we model P(X) with a Poisson distribution with parameter λ > 0, i.e.,
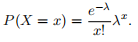
Let P(λ|α, β) be a Gamma prior for λ, where the Gamma probability density function is defined as:
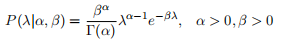
and where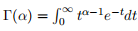 is the Gamma function.
is the Gamma function.
is the Gamma function.
Assume you are working with a collaborator (e.g., a medical researcher or a scientist) who collected a data set D = {x1, . . . , xN } and asks you to do parameter estimation for λ for a Poisson model. However, instead of giving you the original data D = {x1, . . . , xN } your collaborator instead has thrown away the original data D and just gives you two numbers: (i) the value of N, and (ii) the average of the xi’s,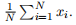 You can assume that the xi’s are conditionally independent given λ.
You can assume that the xi’s are conditionally independent given λ.
You can assume that the xi’s are conditionally independent given λ.
Answer the following questions.
- Define the likelihood L(λ) for this problem in terms of the information that the collaborator provided.
- Is the Gamma density a conjugate prior for the Poisson likelihood? Provide a Yes or No answer, and provide a proof to support your answer in the form of equations.
Problem 6: Bayesian Active Learning with Multi-Armed Bandits (30 points)
An active area of machine learning research is multi-armed bandits. In this problem we will see how Bayesian modeling can be useful in this context. We will only explore one small aspect of multi-armed bandit problems: there is a large literature in machine learning on this topic in general.
Introduction and Algorithm Description
Consider a setup where we have K “bandits,” each with an “arm.” You can think of each bandit as being a slot machine (as in gambling) with an arm that we can pull. Whenever we pull a particular arm k (for bandit k) we get a stochastic reward yk ∈ {0, 1} that is drawn from some unknown Bernoulli distribution θk, where we have binary random variables Yk (one per bandit) with (unknown) parameters θk = P(yk = 1), k = 1, . . . , K.
The bandit problem we will investigate is how to sequentially explore/select arms to try to identify which of the arms (or bandits) has the highest expected reward, i.e., the goal is to identify arg maxk{θk} as quickly and accurately as we can. This problem shows up in a variety of real-world problems in areas like reinforcement learning, active learning, medical clinical trials, online advertising, and so on.
In general we will consider N sequential trials indexed by i = 1, . . . , N. At the start of each trial i we select one arm k: we then “pull” that arm and we get a random yk outcome (0 or 1) drawn from the true θk for the arm we pulled. We only pull one arm per trial; we then move on to trial i + 1, select one of the K arms based on the information available up to that point, and pull that arm; and so on.
In terms of notation, after we have conducted trial i, 1 ≤ i ≤ N we will have 2 numbers for each of the K arms. The first number is n
(
k
i)
, the number of times that arm k has been “pulled” (selected in a trial) up to and including trial i. The second number is 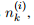 , the number of times that outcome yk = 1 has been observed up to and including trial i. In general 0 ≤ r
, the number of times that outcome yk = 1 has been observed up to and including trial i. In general 0 ≤ r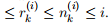 .
.
, the number of times that outcome yk = 1 has been observed up to and including trial i. In general 0 ≤ r.
We will investigate three different algorithms for selecting an arm k at each trial and we will explore how they differ:

where αk and βk are parameters of a Beta prior for each θk. If there is a tie among multiple arms in the equation above, then select one of the tied arms uniformly at random.
3. Thompson Sampling: This algorithm keeps track of a Beta posterior density for each arm k, which(before it selects an arm for trial i). The Beta density will be a function of the following numbers: 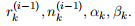 At the start of each trial i it then samples θk values, one from each of the K arms using the current posterior Beta densities for each arm. It then selects the arm k whose sampled value has the highest value among the K sampled values. (Again break ties uniformly at random if there is a tie, but since we are sampling continuous-valued θs, the probability of a tie in sampling is near zero).
At the start of each trial i it then samples θk values, one from each of the K arms using the current posterior Beta densities for each arm. It then selects the arm k whose sampled value has the highest value among the K sampled values. (Again break ties uniformly at random if there is a tie, but since we are sampling continuous-valued θs, the probability of a tie in sampling is near zero).
At the start of each trial i it then samples θk values, one from each of the K arms using the current posterior Beta densities for each arm. It then selects the arm k whose sampled value has the highest value among the K sampled values. (Again break ties uniformly at random if there is a tie, but since we are sampling continuous-valued θs, the probability of a tie in sampling is near zero).
In general we would like to have an algorithm that can both (i) explore the arms (which Random will do, but Greedy won’t do enough of), but (ii) also exploit the arms (by focusing on the more promising ones - which Random won’t do, and Greedy will sometimes do too much of). Thompson Sampling provides a balance between these two extremes of exploring and exploiting. As you might imagine, the Greedy method can sometimes be quite suboptimal and since it can get “trapped” and not explore the set of arms enough. And it makes sense that there are more efficient strategies than Random.
The intuition for the sampling aspect of Thompson Sampling is that even if, at trial i, an arm only has a small probability of being the highest reward arm, there is still a chance of it being selected since it might possibly turn out to be the optimal arm in the long run once we see more data (hence, Thompson Sampling encourages some exploration, in a Bayesian fashion). The general idea of Thompson Sampling has some nice theoretical properties (see the discussion in Section 8 of the Russo et al tutorial).
For optional additional reading, for a more complete description of Thompson Sampling for Bernoulli bandits (which is the problem we described above) you can read Sections 1 through 3 of the following tu torial by Russo et al on Thompson Sampling: https://arxiv.org/pdf/1707.02038.pdf. Theoretical properties are discussed in Section 8.
Your goal is to implement in code (in any language you wish) the three algorithms, Greedy, Random, and Thompson Sampling and then evaluate these methods using the instructions below.
Experiments across Multiple Runs
You will implement the 3 algorithms and explore how they work on simulated problems. A single “run” consists of N trials: each run can produce different results since the yk values are stochastic for each trial i, and in addition the Random and Thompson Sampling algorithms have randomness built into how they select arms to pull.
Thus, any single run can be quite noisy due to the stochasticity of the problem. So, to average over this stochastic noise (in terms of evaluating systematic differences between algorithms), you will generate M runs for each algorithm (independently, with different random outcomes for the selected arms each time, and potentially different random selections of arms at each trial), where each run is of length N. Thus, for each of the 3 algorithms you will end up with M runs each with N trials, and sets of numbers n
(
k
i)
and r (i) k , k = 1, . . . , K arms, and i = 1, . . . , N trials, for each of the M runs.
Note 1: it is important that the runs are as random as you can make them. So its fine to set a random seed before you run any of the M runs (this can be helpful in debugging so that you simulate the same “random” sequence of trials across runs), but don’t reset the seed to the same value at the start of each run (if you do reset the seed, each run will produce the same result (since each run will be using the same sequence of pseudorandom numbers) which we don’t want).
Note 2: since the outcomes yk are random for any trial i, it doesn’t matter how you order the execution of the 3 algorithms within your code. You could for example have an outer loop over the 3 algorithms and then generate all of the results for M runs for one algorithm before generating all results for M runs for the next. Or you could have a loop over m = 1, . . . , M runs and run each of the 3 algorithms per run before you go to the next run. Or you could loop over each trial i = 1, . . . , N (for each run), and have the loop over the 3 algorithms be in the inner-most part of the loop. Some versions may be more efficient than others in terms of execution time, but all orderings should produce the same results on average (at least for large M).
Evaluation Methods
To evaluate how good an algorithm is on average after i trials, you can compute the average accuracy (across M runs) after each trial i = 1, . . . , N. The performance metric we will use is the success rate, i.e., the fraction of times (across runs) that an algorithm’s estimate of the best arm (i)
, after i trials, is the same as the true best arm k
∗ = arg maxk θk, where the θk’s are the true parameters for each arm. The true best arm is known to us for evaluation purposes but is not known to the algorithms. For each value i, this type of evaluation measures the accuracy on average if we had stopped after only i trials instead of doing all N, and allows us to plot accuracy as a function of i.
At the end of each trial i, for each of the 3 algorithms we will use the MPE equation from earlier to select the best arm from that algorithm’s perspective, at that point in the run, i.e., select arg maxk{θk
MP E}. Note that θk
MP E may in general be different for each of the algorithms since they have each collected different data, i.e.,we will in general have different values for n
(
k
i)
and r (i) k , k = 1, . . . , K for each of the 3 algorithms.
You can then plot (on the y-axis) the fraction of correct identifications, i.e., how often the estimate of the best arm, for each of the 3 algorithms, agrees with the true best arm, averaged across the M runs, for each value of i = 1, . . . , N (on the x-axis). The y-axis will range from 0 to 1. The curves will generally start at low values (around 1/K) for small values of i and then increase (at least for Thompson Sampling and Random) towards 1. The rate at which they approach 1 will depend on the values of θk’s and will differ between strategies. Greedy will tend to be the noisiest and least predictable across runs.
Note: to keep your code modular and well-organized, one suggestion is to first run the M trials and produce the results (M × N × K numbers) for each of the 3 algorithms. Then, given all of this data, you can run separate evaluation code that computes the average accuracy (as a function of i), for each algorithm, for each of the 3 algorithms.
Handling Ties: It is important in your code to break ties randomly. In particular, be aware that the standard “max” or “argmax” function in many programming languages will not break ties randomly, e.g., given [0.50.20.50.1], in selecting which index corresponds to the largest value, many functions will always return the first index value of 1 rather than randomly returning 1 or 3. So you may need to write your own (simple) function to do this (i.e., to break ties randomly).
Priors: For simplicity in all the experiments in this problem we will use uniform (uninformative) prior values of αk = βk = 1, k = 1, . . . , K.
What to Submit:
1. Submit the plots requested below for this problem. Use M = 500 for all your plots and generate 3 graphs, one for each setting of the θ’s below, where each graph has 3 curves (one per algorithm) and the x-axis runs from 1 to N. Feel free to make M much larger (e.g, M = 10, 000) if you want to get smoother plots and if your code runs fast enough to do more runs.
2. Please submit your code in your programming language of choice at the end of your solution file. You can put everything in a single file where the main function/script generates the figures; or if you have multiple files then submit a Zip file and include a single script file to generate the figures.
• Let K = 10 with θ1 = 0.9, θ2 = 0.8, θ3 = θ4, . . . = θ10 = 0.5. For N = 1000 trials plot the success rate for each of the three strategies.
• Repeat part 1 (i.e., generate another plot) but now with θ1 = 0.9, θ2 = 0.88, θ3 = θ4, . . . = θ10 = 0.5. Set N = 3000 trials.
• Repeat part 1 (i.e., generate another plot) but now with θ1 = 0.9, θ2 = θ3 = θ4, . . . = θ10 = 0.85. Set N = 3000 trials.
• Comment on (i) the differences in results between the 3 algorithms for each plot, and (ii) the differ ences in results in general between the 3 plots as the true θ’s change.
• Optional: (no extra credit but fun to think about): for the random strategy, can you think of how you might analytically compute the success rate as a function of i (rather than simulating it) if you knew the θ’s. You could just consider the special case of K = 2 bandits. What insights can you gain from your analysis? i.e., in terms of how hard or easy a particular identification problem is.
Note that you should be able to get your code to run fairly quickly, e.g., in less than a minute for each of the plots being requested, if your code is reasonably efficient. You may want to make sure your code is working first (e.g., try an “easy” problem first for debugging with just K = 2 arms and a large difference in the theta values).
Finally, as a sidenote for those of you who may be interested, here is a pointer to a paper in 2021 from my research group where we used ideas from Bayesian estimation, multi-arm bandits, and Thompson sampling to address the problem of assessing the accuracy of black-box classification models https://arxiv.org/pdf/2002.06532.pdf (Ji et al, AAAI Conference, 2021).