Hello, if you have any need, please feel free to consult us, this is my wechat: wx91due
COMP3702 Artificial Intelligence (Semester 2, 2024) Assignment 2: BeeBot MDP
Key information:
- Due: 1pm, Friday 20 September 2024
- This assignment assesses your skills in developing discrete search techniques for challenging problems.
- Assignment 2 contributes 20% to your final grade.
- This assignment consists of two parts: (1) programming and (2) a report.
- This is an individual assignment.
- Both code and report are to be submitted via Gradescope (https://www.gradescope.com/). You can find a link to the COMP3702 Gradescope site on Blackboard.
- Your code (Part 1) will be graded using the Gradescope code autograder, using the testcases in the support code provided at https://github.com/comp3702/2024-Assignment-2-Support-Code.
- Your report (Part 2) should fit the template provided, be in .pdf format and named according to the format a2-COMP3702-[SID].pdf. Reports will be graded by the teaching team.
The BeeBot AI Environment
For A2, the BeeBot environment has been extended to model non-deterministic outcomes of actions. Cost and action validity are now replaced by a reward function where action costs are represented by negative received rewards, with additional penalties (i.e., negative rewards) being incurred when a collision occurs (between the Bee or a honey Widget and an obstacle, or between Widgets). Updates to the game environment are indicated in pink font.
Levels in BeeBot are composed of a Hexagonal grid of cells, where each cell contains a character representing the cell type. An example game level is shown in Figure 1.
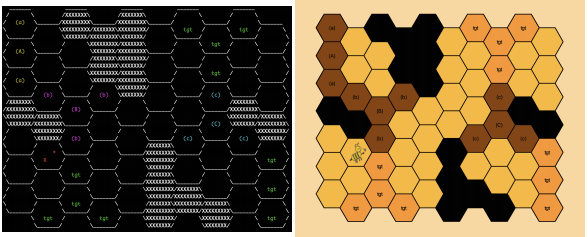
Figure 1: Example game level of BeeBot, showing character-based and GUI visualiser representations
Environment representation
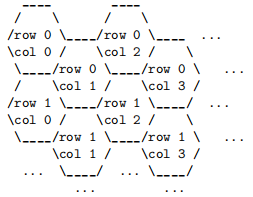
Two cells in the hex grid are considered adjacent if they share an edge. For each non-border cell, there are 6 adjacent cells.
The BeeBot Agent and its Actions
At each time step, the agent is prompted to select an action. The Bee has 4 available nominal actions:
- Forward → move to the adjacent cell in the direction of the front of the Bee (keeping the same orientation)
- Reverse → move to the adjacent cell in the opposite direction to the front of the Bee (keeping the same orientation)
- Spin Left → rotate left (relative to the Bee’s front, i.e. counterclockwise) by 60 degrees (staying in the same cell)
- Spin Right → rotate right (i.e. clockwise) by 60 degrees (staying in the same cell)
Additionally, there is a fixed probability (also given as a parameter of each testcase) for the Bee to ‘double move’, i.e. perform the nominal selected action twice. The probability of a double move occurring depends on which action is selected. Double movement may occur simultaneously with drift (CW or CCW).
The reward received after each action is the minimum/most negative out of the rewards received for the nominal action and any additional (drift/double move) actions.
Action Costs
If the Bee moves without pushing or pulling a honey widget, the cost of the action is given by a base action cost, ACTION_BASE_COST[a] where ‘a’ is the action that was performed.
The costs are detailed in the constants.py file of the support code:
Obstacles
Additionally, the environment now contains an additional obstacle type, called ‘thorns’. Thorns behave in the same way as obstacles, but when collision occurs, a different (larger) penalty is received as the reward. As a result, avoiding collisions with thorns has greater importance than avoiding collisions with obstacles. Thorns are represented by ‘!!!’ in the text-based visualisation and red cells in the graphical visualisation.
Widgets
In the visualisation, each honey Widget in the environment is assigned a unique letter ‘a’, ‘b’, ‘c’, etc. Cells which are occupied by a honey Widget are marked with the letter assigned to that Widget (surrounded by round brackets). The centre position of the honey Widget is marked by the uppercase version of the letter, while all other cells occupied by the widget are marked with the lowercase.
Three honey widget types are possible, called Widget3, Widget4 and Widget5, where the trailing number denotes the number of cells occupied by the honey Widget. The shapes of these three honey Widget types and each of their possible orientations are shown in Figures 3 to 5 below.
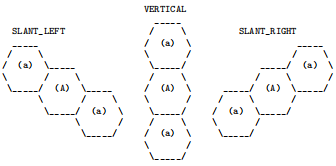
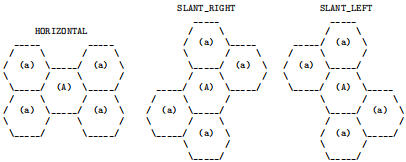
orientation).
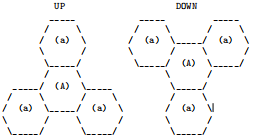
Translation occurs when the Bee is positioned with its front side adjacent to one of the honey widgets’ cells such that the Bee’s orientation is in line with the honey widget’s centre position. Translation results in the centre position of the widget moving in the same direction as the Bee. The orientation of the honey Widget does not change when translation occurs. Translation can occur when either ‘Forward’ or ‘Reverse’ actions are performed. For an action which results in translation to be valid, the new position of all cells of the moved widget must not intersect with the environment boundary, obstacles, the cells of any other honey Widgets or the Bee’s new position.
Rotation occurs when the Bee’s new position intersects one of the cells of a honey Widget but the Bee’s orientation does not point towards the centre of that widget. Rotation results in the honey widget spinning around its centre point, causing the widget to change orientation. The position of the centre point does not change when rotation occurs. Rotation can only occur for the ‘Forward’ action - performing ‘Reverse’ in a situation where ‘Forward’ would result in a widget rotation is considered invalid.
The following diagrams show which moves result in translation or rotation for each honey Widget type, with the arrows indicating directions from which the Bee can push or pull a widget in order to cause a translation or rotation of the widget. Pushing in a direction which is not marked with an arrow is considered invalid.
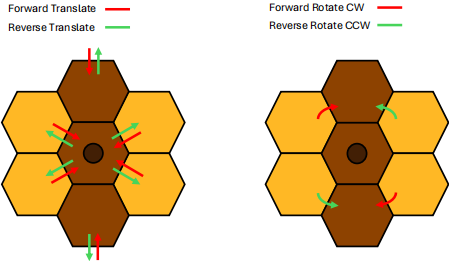
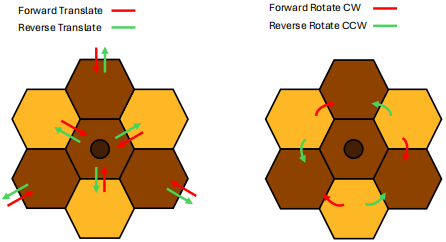
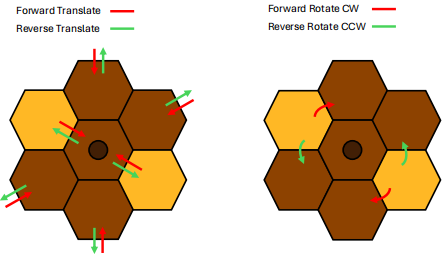
Targets
Interactive mode
$ python play_game.py <input_file>.txt
$ python play.py <input_file>.txt
where <input_file>.txt is a valid testcase file (from the support code, with path relative to the current directory), e.g. testcases/ex1.txt.
Depending on your python installation, you should run the code using python, python3 or py.
In interactive mode, type the symbol for your chosen action (and press enter in the command line version) to perform the action: press ’W’ to move the Bee forward, ’S’ to move the Bee in reverse, ’A’ to turn the Bee left (counterclockwise) and ’D’ to turn the Bee right (clockwise). Use ’Q’ to quit the simulation, and ’R’ to reset the environment to the initial configuration.
BeeBot as an MDP
What is provided to you
- A class representing BeeBot game map and a number of helper functions
- A parser method to take an input file (testcase) and convert it into a BeeBot map
- A tester
- Testcases to test and evaluate your solution
- A script to allow you to play BeeBot interactively
- A solution file template
Your assignment task
Your task is to develop algorithms for computing policies, and to write a report testing your understanding of and analysing the performance of your algorithms. You will be graded on both your submitted code (Part 1, 60%) and the report (Part 2, 40%). These percentages will be scaled to the 20% course weighting for this assessment item.
The provided support code formulates BeeBot as an MDP, and your task is to submit code implementing the following MDP algorithms:
- Value Iteration (VI)
- Policy Iteration (PI)
Individual testcases specify which strategy (value iteration/policy iteration) will be applied, but you may modify the strategy specified in your local copy of the test cases for the purpose of comparing the performance of your two algorithms. Note that any local changes you make to the test cases will not modify the test cases on Gradescope (against which your programming component will be graded). The difficulty of higher level testcases will be designed to require a more advanced solution (e.g. linear algebra policy iteration).
Once you have implemented and tested the algorithms above, you are to complete the questions listed in the section “Part 2 - The Report” and submit the report to Gradescope.
More detail of what is required for the programming and report parts are given below.
Part 1 — The programming task
Interaction with the testcases and autograder
Information on the BeeBot implementation is provided in the Assignment 2 Support Code README.md and code comments.
Implement your solution using the supplied solution.py template file. You are required to fill in the following method stubs:
You can add additional helper methods and classes (either in solution.py or in files you create) if you wish.
To ensure your code is handled correctly by the autograder, you should avoid using any try-except blocks in your implementation of the above methods (as this can interfere with our time-out handling). Refer to the documentation in solution.py for more details.
Grading rubric for the programming component (total marks: 60/100)
- Agent successfully reaches the goal
- Total reward
- Time elapsed
- Iterations performed
- Each test case has targets for total reward, time elapsed, and iterations performed.
- Maximum score is achieved when your program matches or beats the target in each category
- Partial marks are available for up to 1.3x total reward, 2x time elapsed and 1.3x number of iterations
- Total mark for the test case is a weighted sum of the scores for each category
- Total code mark is the sum of the marks for each test case
Part 2 — The report
The report tests your understanding of the methods you have used in your code, and contributes 40/100 of your assignment mark. Please make use of the report templates provided on Blackboard, because Gradescope makes use of a predefined assignment template. Submit your report via Gradescope, in .pdf format, and named according to the format a2-COMP3702-[SID].pdf, where SID is your student ID. Reports will be graded by the teaching team.
Your report task is to answer the questions below, in the report template provided.
Question 1. MDP problem definition (15 marks)
i) Define the four components in relation to BeeBotii) Identify where they are represented in your code
c) State and briefly justify what the following dimensions of complexity are for the BeeBot MDP agent: (2.5 marks)
• Planning Horizon• Sensing Uncertainty• Effect Uncertainty• Computational Limits• Learning
Question 2. Comparison of algorithms and optimisations (15 marks)
a) Describe your implementations of Value Iteration and Policy Iteration in one sentence each. Include details such as whether you used asynchronous updates, and how you handled policy evaluation in PI. (2 marks)
• Time to converge to the solution. (3 marks)• Number of iterations to converge to the solution. (3 marks)
You should report the numerical results in a neatly formatted table (not screenshots from your computer or Gradescope).
Question 3. Investigating optimal policy variation (10 marks)
Consider testcase ex6.txt, which includes a risky (but lower cost) path through the top half of the grid, and a less risky (but higher cost) path through the bottom half of the grid. Explore how the policy of the agent changes with thorn penalty and transition probabilities.
If you did not implement PI, you may change the solver type to VI in order to answer this question.
b) Picking three suitable values for thorn penalty and three suitable values for the transition probabilities, explore how the optimal policy changes over the 9 combinations of these factors. Present the results in a table, clearly denoting the optimal behaviour (i.e. top/risky, bottom/safe, something else) for each combination. Do the experimental results align with what you thought should happen? If not, why? (5 marks)
References and Generative AI
Academic Misconduct
It is the responsibility of the student to ensure that you understand what constitutes Academic Misconduct and to ensure that you do not break the rules. If you are unclear about what is required, please ask.
In the coding part of COMP3702 assignments, you are allowed to draw on publicly-accessible resources and provided tutorial solutions, but you must make reference or attribution to its source, in comments next to the referenced code, and include a list of references you have drawn on in your solution.py docstring.
• https://guides.library.uq.edu.au/referencing/chatgpt-and-generative-ai-tools
Failure to reference use of generative AI tools constitutes student misconduct under the Student Code of Conduct.
All submitted files (code and report) will be subject to electronic plagiarism detection and misconduct proceedings will be instituted against students where plagiarism or collusion is suspected. The electronic plagiarism detection can detect similarities in code structure even if comments, variable names, formatting etc. are modified. If you collude to develop your code or answer your report questions, you will be caught.
• Information regarding Academic Integrity and Misconduct:
– https://my.uq.edu.au/information-and-services/manage-my-program/student-integrity-and-conduct/academic-integrity-and-student-conduct
– http://ppl.app.uq.edu.au/content/3.60.04-student-integrity-and-misconduct
• Information on Student Services:
– https://www.uq.edu.au/student-services/
Late submission
It may take the autograder up to an hour to grade your submission. It is your responsibility to ensure you are uploading your code early enough and often enough that you are able to resolve any issues that may be revealed by the autograder before the deadline. Submitting non-functional code just before the deadline, and not allowing enough time to update your code in response to autograder feedback is not considered a valid reason to submit late without penalty.
In the event of exceptional circumstances, you may submit a request for an extension. You can find guide-lines on acceptable reasons for an extension here https://my.uq.edu.au/information-and-services/manage-my-program/exams-and-assessment/applying-extension, and submit the UQ Application for Extension of Assessment form.