Hello, if you have any need, please feel free to consult us, this is my wechat: wx91due
COMP24112 Summative Exercise: Air Quality Analysis (30 Marks)
This lab exercise is about air quality analysis, where you will predict air quality through solving classification and regression tasks. You will submit a notebook file, a pdf report, and a trained model. You will be marked for implementation, design, result and analysis. Your code should be easy to read and your report should be concise (max 600 words). It is strongly recommended that you use a LaTeX editor, such as Overleaf (https://www.overleaf.com/), to write your report.
Please note your notebook should take no more than 10 minutes to run on lab computers. There is 1 mark for code efficiency.
1. Dataset and Knowledge Preparation
The provided dataset contains measurements of air quality from a multisensor device. The device used spectrometer analyzers (variables marked by "GT") and solid state metal oxide detectors (variables marked by "PT08.Sx"), as well as temperature (T), relative humidity (RH) and absolute humidity (AH) sensors.
The dataset contains 3304 instances of hourly averaged measurements taken at road level in a polluted city. You will predict the CO(GT) variable representing carbon monoxide levels. There are missing features in this dataset, flagged by the number -999 .
You will need to pre-process the dataset to handle missing features, for which please self-learn from scikit-learn on how to impute missing values (https://scikit-learn.org/stable/modules/impute.html). You will need to split the dataset into training and testing sets, also to run cross validation, when you see fit. For this, please self-learn from scikit-learn on data splitting (https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html) and cross validation (https://scikit-learn.org/stable/modules/cross_validation.html).
In [1]:
2. Linear Classification via Gradient Descent (13 marks)
The air quality is assessed using the CO(GT) variable. If it is no greater than 4.5, the air quality is good (CO(GT)<=4.5), otherwise, it is bad (CO(GT)>4.5). You will perform binary classification to predict whether the air quality is good based on the other 11 varivables, i.e., from PT08.S1(CO) to AH.
2.1 Model Training and Testing (4 marks)
This practice is about training a binary linear classifier by minimising a hinge loss with L2 (ridge) regularisation, and then testing its performance. Given a set of training samples , where is the feature vector and is the class label for the -th training sample, the training objective function to minimise is
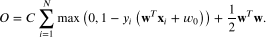
Here, is a column weight vector of the linear model, is the bias parameter of the model, and is the regularisation hyperparameter.
Recall from your lectures that gradient descent is an iterative optimisation algorithm typically used in model training. Complete the implmentation of the training function linear_gd_train below, which trains your linear model by minimising the above provided training objective function using gradient descent.
The function should return the trained model weights and the corresponding objective function value (referred to as cost) per iteration. In addition to the training data, the function should take the regularisation hyperparameter , learning rate , and the number of iterations as arguments. A default setting of these parameters has been provided below, which is able to provide reasonably good performance.
Note that scikit-learn is not allowed for implementation in this section. We recommend that you avoid using for loops in your implementation of the objective function or weight update, and instead use built-in numpy operations for efficiency.
In [11]:
Now, you are ready to conduct a complete experiment of air quality classification. The provided code below splits the data into training and testing sets and imputes the missing features.
In [12]:
Write your code below, which should train the model, plot the training objective function value and the classification accuracy of the training set over iterations, and print the classification accuracy and score of the testing set. Note, use the default setting provided for , and . Your plot should have axis labels and titles.
2.2 Learning Rate Analysis (3 marks)
The learning rate (Greek letter "eta") is a key parameter that affects the model training and performance. Design an appropriate experiment to demonstrate the effect of on model training, and on the model performance during testing.
2.3 Report (6 Marks)
Answer the following questions in your report, to be submitted separately:
1. Derive step-by-step the gradient of the provided training objective function , and the updating equation of your model weights based on gradient descent. (3 marks)
2. What does the figure from section 2.1 tell you, and what is the indication of the classification accuracies of your training and testing sets? (1 mark)
3. Comment on the effect of on model training, and on the model performance during testing, based on your results observed in Section 2.2. (2 marks)
3. Air Quality Analysis by Neural Network (10 marks)
In this experiment, you will predict the CO(GT) value based on the other 11 variables through regression. You will use a neural network to build a nonlinear regression model. Familiarise yourself with how to build a regression model by mutlilayer perceptron (MLP) using the scikit learn tutorial (https://scikit-learn.org/stable/modules/neural_networks_supervised.html#regression (https://scikit-learn.org/stable/modules/neural_networks_supervised.html#regression)).
3.1 Simple MLP Model Selection (4 marks)
This section is focused on the practical aspects of MLP implementation and model selection. We will first compare some model architectures.
The set of MLP architectures to select is specified in param_grid below, including two MLPs with one hidden layer, where one has a small number of 3 hidden neurons, while the other has a larger number of 100 hidden neurons, and two MLPs with two hidden layers, where one is small (3, 3) and the other is larger (100, 100). It also includes two activation function options, i.e., the logistic and the rectified linear unit ("relu"). These result in a total of 8 model options, where sklearn default parameters are used for all the MLPs and their training.
Your code below should do the following: Split the dataset into the training and testing sets. Preprocess the data by imputing the missing features. Use the training set for model selection by cross-validation, and use mean squared error (MSE) as the model selection performance metric. You can use the scikit-learn module GridSearchCV (https://scikit-learn.org/stable/modules/grid_search.html#grid-search) to conduct grid search. Print the cross-validation MSE with standard deviation of the selected model. Re-train the selected model using the whole training set, and print its MSE and R2 score for the testing set.
3.2 Training Algorithm Comparison: SGD and ADAM (2 Marks)
In this exercise, you will compare two training algorithms, stochastic gradient descent (SGD) and ADAM optimisation, for training an MLP with two hidden layers each containing 100 neurons with "relu" activation, under the settings specified in test_params as below.
Write the code below, where each training algorithm should run for 300 iterations (make sure to set early_stopping=False ). For both algorithms, (1) plot the training loss (use the defaul loss setting in sklearn), as well as the MSE of both training and testing sets, over iterations; and (2) print the MSE and score of the trained model using the testing set.
3.3 Report (4 Marks)
1. What conclusions can you draw based on your model selection results in Section 3.1? (2 marks)
2. Comment on the two training algorithms based on your results obtained in Section 3.2. (2 marks)