Assignment 5
Optimization Methods
MET CS777
Description
In this assignment you will implement Batch Gradient Descent to fit a line into a two-dimensional data set. You will implement a set of Spark jobs that will learn parameters of a line model using the New York City Taxi trip in the Year 2013 dataset. The dataset was released under the FOIL (The Freedom of Information Law) and made public by
Chris Whong (https://chriswhong.com/open-data/foil_nyc_taxi/). See the Assignment 1 for details of the dataset.
In this assignment you will implement a linear model using travel distance in miles to predict the fare amount, the money that is paid to the taxis.
Please note that it is NOT allowed to useSpark ML and MLlib libraries in this assignment.
Taxi Dataset
This is the same dataset as Assignment 1. Please refer to there for the data description.
The dataset is in Comma Separated Volume Format (CSV). When you read a line and
split by comma sign (”,”), you will get a string array of length 17. Index number startes from zero. For the assignment, you need to get trip distance in miles (index 5) and fare amount in dollars (index 11) as stated in the following table.
|
index 5 (X-axis) |
trip distance |
trip distance in miles |
|
index 11 (Y-axis) |
fare amount |
fare amount in dollars |
Table 1: Taxi Data Set fields
Data Clean-up Step
• Remove all taxi rides that are less than 2 mins or more than 1 hour.
• Remove all taxi rides that have ”fare amount” less than 3 dollars or more than 200 dollars
• Remove all taxi rides that have “trip distance” less than 1 mile or more than 50 miles.
• Remove all taxi rides that have “tolls amount” less than 3 dollars.
Note: Preprocess the data and store the results in your cluster storage.
You can download or access the datasets using following internal URLs:
|
AWS |
|
|
Small Data Set |
|
|
Large Data Set |
|
Table 2: Datasets on AWS
Small dataset (93 MB compressed, uncompressed 384 MB) is for code development, implementation, and testing with roughly 2 million taxi trips.
Tasks
Task 1 (20 points): Simple Linear Regression
Find a simple line regression model to predict “fare amount” from the travel distance.
Consider a Simple Linear Regression model given in equation (1). The solutions for slope of the line, m, andy-intercept, b, are calculated in the equations (2) and (3).
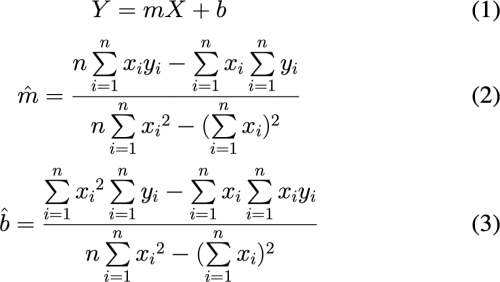
Implement a PySpark job that calculates the exact answers for the parameters m and b.
Run your implementation on the large data set and report the computation time for your Spark Job for this task. You can get the execution time for the cloud services that you use.
Note: Execution of this task on the large dataset depends on your implementation and can take a long time. For example, on a cluster with 12 cores in total, it takes more than 40 min computation time.
Task 2 (40 Points) Find the Parameters using Gradient Descent
In this task, you should implement the batch gradient descent to find the optimal parameters for the Simple Linear Regression model.
• Load the data into spark cluster memory as RDD or Dataframe.
• Start with all parameter’s initial values equal to 0.1.
• Run for gradient descent for 100 iterations.
Cost function will be:
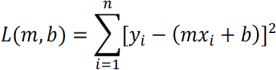
Partial Derivatives to update the parameters m and b are as follows:
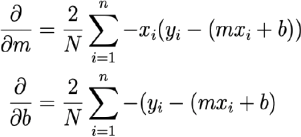
Here is a list of important setup parameters:
• Set your initial learning rate to be learningRate=0.0001 and change it if needed.
• You can implement the bold driver to improve your learning rate.
• Maximum number of iterations is 100, numIteration=100 .
Run your implementation on the large data set and report the computation time for your Spark Job for this task. Compare the computation time with the previous task.
Printout the cost for each iteration.
Printout the model parameters, (m, b) in each iteration.
Note: You might write some code for the gradient descent in PySpark that can work perfectly on your laptop but does not run on a cluster. The main reason is that on your laptop it is running in a single process while on a cluster it runs on multiple processes (shared-nothing processes). You need to be careful to reduce all of jobs/processes to be able to update the variables. Otherwise, each process will have its own variables.
Task 3 (40 Points): Fit Multiple Linear Regression using Gradient Descent
We would like to find a linear model with 4 variables to predict total paid amounts of Taxi rides. The following table describes the variables that we want to use.

Table 4: Taxi Dataset fields.
Here is a list of important setup parameters:
• Initialize all parameters to 0.1.
• Set your learning rate to learningRate=0.001 .
• Maximum number of iterations to 100, numIteration=100 .
• Use Vectorization for this task. We will not accept your solution when you write duplicated code. It should include vectorization.
• Implement “ Bold Driver” technique to dynamically change the learning rate. (10 points of 40 points)
Printout the costs in each iteration.
Printout the model parameters in each iteration.
Submission Guidelines
● Naming Convention:
METCS777-Assignment5-[TaskX-Y]FIRST+LASTNAME.[pdf/py/ipynb]
Where:
o [TaskX-Y] doesn’t apply for .[pdf] files
o No space between first and lastname
● Files:
o Create one document in pdf that has screenshots of running results of all coding problems. For each task, copy and paste the results that your lastSpark job saved in the bucket. Also, for each Spark job, include a screenshot of the Spark History. Explain clearly and precisely the results.
Figure 1: Screenshot of Spark History
o Include output file for each task.
o Please submit each file separately (DO NOT ZIP them!!!).
● For example, sample submission of John Doe’s Assignment 5 should be the following files:
o METCS777-Assignment5-JohnDoe.pdf
o METCS777-Assignment5-Task1-3-JohnDoe.ipynb
o METCS777-Assignment5-Task1-JohnDoe.py
o METCS777-Assignment5-Task1-Output-JohnDoe.txt
o …
Evaluation Criteria for Coding Tasks

Academic Misconduct Regarding Programming
In a programming class like this, there is sometimes a very fine line between “cheating” and acceptable and beneficial interaction between peers. Thus, it is very important that you fully understand what is and what is not allowed in terms of collaboration with your classmates. We want to be 100% precise,so that there can be no confusion.
The rule on collaboration and communication with your classmates is as follows: you cannot transmit or receive code from or to anyone in the class in anyway —visually (by showing someone your code), electronically (by emailing, posting, or otherwise sending someone your code), verbally (by reading code to someone) or in any other way we have not yet imagined. Any other collaboration is acceptable.
It is not allowed to collaborate and communicate with people who are not your classmates (or your TAs or instructor). This means posting any questions of any nature to programming forums such as StackOverflow is strictly prohibited. As far as going to the web and using Google, we will apply the “two-line rule”. Go to any web page you like and do any search that you like. But you cannot take more than two lines of code from an external resource and include it in your assignment in any form. Note that changing variable names or otherwise transforming or obfuscating code you found on the web does not render the “two-line rule” inapplicable. It is still a violation to obtain more than two lines of code from an external resource and turn it in, whatever you do to those two lines after you first obtain them.
Furthermore, you must always cite your sources. Add a comment to your code that includes the URL(s) that you consulted when constructing your solution. This turns out to be very helpful when you’re looking at something you wrote a while ago and you need to remind yourself what you were thinking.